-
[Semantic Segmentation] FCNComputer Vision & AI/Computer Vision 2024. 2. 10. 17:44
FCN
Fully Convolutional Network
end-to-end 딥러닝 모델의 기본인 FCN
end-to-end 딥러닝 모델
입력부터 출력까지 프로세스를 하나의 모델로 구현한 것특징
- VGG 네트워크 backbone을 그대로 사용
- VGG 네트워크의 FC Layer (nn.Linear)를 Convolution으로 대체함
- Transposed Convolution을 이용해서 Pixel Wise prediction을 수행함

VGG
3x3의 convolution을 깊게 쌓아서 적은 파라미터로 효과적으로 receptive field를 넓히면서
높은 성능을 달성한 네트워크

Convolutional Layer를 사용한 이유
왜 nn.Linear 에서 nn.Conv2d 를 채택했을까?

기존 Fully Connected Layer는 flatten과정에서 픽셀의 위치정보를 해치게 된다.
단순 classification문제에서는 상관없으나
segmentation 은 pixel 위치정보가 중요하기 때문에 Convolutional Layer를 사용한다.
또한 추가적인 장점은,
다른 이미지 입력 사이즈에 상관없이 학습, 추론이 가능하다.
그 이유는 다음과 같다.
nn.Conv2d(input_channel, output_channel, kernel_size, ...) nn.Linear(input_channel * height * width, output_size)nn.Linear의 인자로 height, width가 포함된다. 즉, input size가 맞아야 학습이 가능하다.
그러나 nn.Conv2는 input channel만 고정되면 상관이 없다.
Pixel Wise Prediction
Transposed Convolution
위 그림을 다시 보면,
Convolution Layer를 통해서 특징을 추출하는데
중간중간 max pooling으로 결과적으로 이미지를 1/32만큼 축소한다.
그러나 우리는 pixel 위치 정보가 중요한 Segmentation task를 해야하기 때문에
7x7을 다시 224x224로 늘려야 한다.
이때 Upsampling을 사용한다.
Upsampling = Deconvolution = Transposed Convolution
모두 같은 용어인데,
convolution의 반대 과정이라 Deconvolution (실제 연산 과정도 convolution연산의 반대이다.)
매트릭스 형태로 봐도 Transposed 된 형태로 계산이 진행된다.

이때, Transposed Convolutioin 값도 Backpropagation에서 Update 된다.
convolution연산과 마찬가지로 stride, padding을 통해 사이즈를 조정할 수 있다.
예를들어, 더 큰 사이즈를 만들고 싶다면 stride를 늘린다.
FCN에서 성능을 향상시키기 위한 방법

논문의 Figure를 보면
FCN-32s일 때, GT와 비교해서 디테일한 정보들이 많이 손실되어 있음을 볼 수 있다.
이러한 이유는 Conv 블록 마지막에 Pooling을 적용할 때마다 1/2만큼 리사이즈 되는데
1/32만큼 리사이즈 된 정보를 한번에 Upsampling하면서 정보가 손실되었기 때문이다.
이를 해결하기 위해서 Skip Connection을 적용한다.
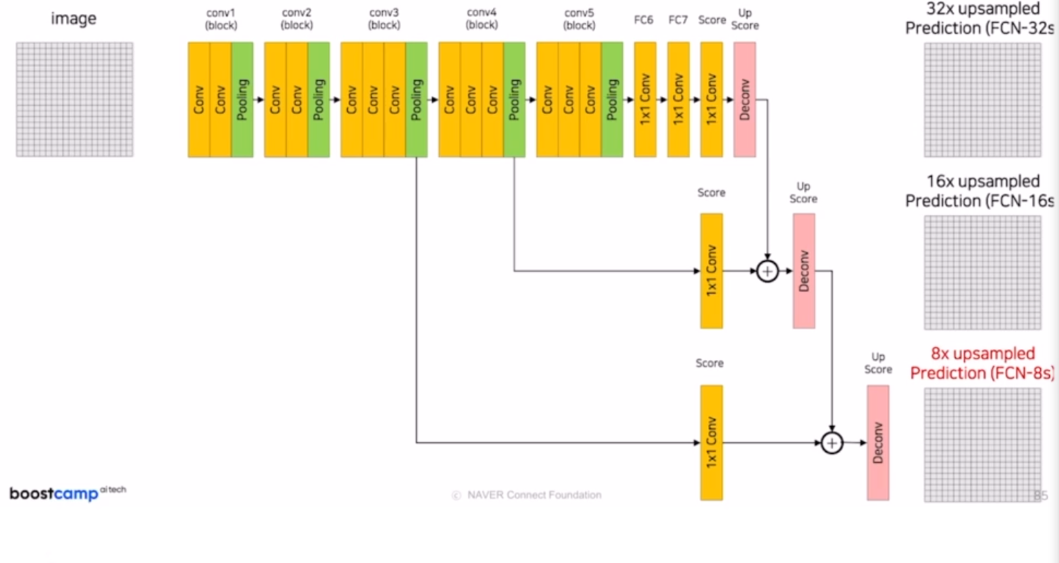
Pooling에 의해 정보를 잃어버리기 전에 연산을 적용해서 정보를 기억할 수 있다.
만약 크기가 맞지 않는다면 crop을 적용한다.
Pixel Accuracy

논문에서 Score 평가지표로 사용된 Pixel Accuracy

Pixel Accuracy = True pixel / Total pixel
'Computer Vision & AI > Computer Vision' 카테고리의 다른 글
[Segmentation] DeconvNet, SegNet, FC DenseNet, DeepLab, DilatedNet (0) 2024.02.22 재활용 쓰레기 분류를 위한 Object Detection 대회 회고 (0) 2024.01.23 [컴퓨터비전] 두 이미지의 유사성을 측정하는 "SSIM" (0) 2023.10.31 classifier prediction을 할 수 있는 웹사이트 (0) 2023.10.17 SAM - Segment Anything Model (1) 2023.10.17