-
[AI 프리코스] 07 Numpy 정리개발자노트/네이버 부스트캠프 AI 2023. 10. 25. 23:00
다항식을 행렬 형태로 표현할 수 있음.
→ 리스트로만 표현하기에는 비효율적인 부분이 있음.
numpy
: numerical python
=고성능 과학 계산용 패키지
특징
- list에 비해 빠르고, 메모리 효율적
- 반복문 없이 데이터 배열 처리 지원
- 선형대수 관련된 다양한 기능 제공
- C, C++ 언어와 통합 가능
ndarray
ex_array = np.array([1,2,3], float) # dtype리스트는 주소값을 저장함.
넘파이 array는 차례대로 데이터를 저장함.
- shape : dimension 반환
- dtype : 데이터 타입 반환 (괄호 안 씀!)
- ndim : dimension의 rank
- size : 데이터 갯수
Handling shape
reshape
(2,4) → (8,)
np.array(ex_mat).reshape(2,4)-1을 넣어주면 나머지 값들을 고려해서 자동으로 값이 할당됨.
flatten
다차원 array를 1차원으로 변환
np.array(ex_mat).flatten()※ 저장이 되는 것은 아님!
Indexing
a[0,0] 와 a[0][0] 는 같음
✅Slicing
a[:, 2:] # 전체 row의 2열부터 a[1, 1:3] # 1 row의 1~2열 a[1:3] # 1 row ~ 2 row 의 전체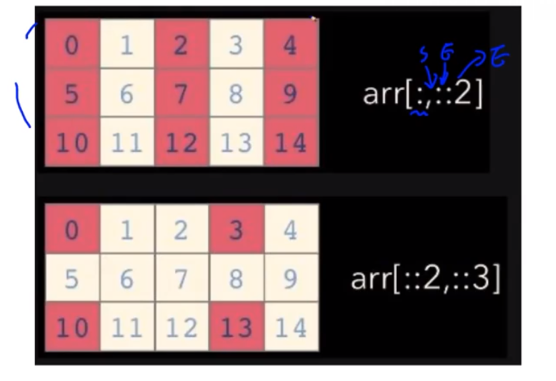
이렇게 건너 뛰면서 step을 줄 수도 있음.
creation function
arange
np.arange(30) np.arange(0, 5, 0.5) np.arange(30).reshape(5,6)list 의 range와 같은 효과
# np.zeros(shape, dtype, order) np.zeros(shape=(10,), dtype=np.int8) np.zeros((2,5)) # np.ones(shape, dtype, order) np.ones(shape=(10,), dtype=np.int8) np.ones((2,5)) # shape만 있고 비어있는 ndarray생성 np.empty(shape=(10,), dtype=np.int8) np.empty((3,5)) #실행할때마다 값이 계속 달라짐 np.zeros_like(original_arr) # 기존의 배열을 기반으로 shape과 dtype이 같은 배열을 생성함identity
단위행렬(i행렬) 생성
np.identity(n=3, dtype=np.int8) np.indentity(5)eye
대각선이 1인 행렬
k값의 시작 index변경 가능
np.eye(3) np.eye(3,5,k=2) np.eye(N=3, M=5, dtype=np.int8)diag
대각선을 추출함
k 로 시작 지정 가능
np.diag(ex_mat)random sampling
np.random.uniform(0,1,10).reshpae(2,5) # 균등분포 np.random.normal(0,1,10).reshape(2,5) # 정규분포 np.random.exponential(scale=2, size=100)
operation functions
sum
ex_array.sum() ex_array.sum(dtype=np.float)axis
모든 operation function을 실행할 때 기준이 되는 dimension축
💡axis방향 중요!

concatenate
vstack : 위 아래 붙임
hstack : 왼쪽 오른쪽 붙임
transpose 전치행렬
mat_a.T
broadcasting 연산 주의
comparisons
a = np.arange(10) a < 4 # 원소 각각을 비교한 boolean array np.all(a>5) # and 와 같은 역할, 모두 true 여야 -> true np.any(a>5) # or 와 같은 역할, 하나라도 true면 -> true np.logical_and(a>0, a<3) np.logical_not(b) # t->f , f->t #where은 두가지 방법이 있음 np.where(a > 0, 3, 2) # true일때는 3이, false일때는 2가 들어감 : where(condition, TRUE, FALSE) np.where(a>5) # 참인것의 index를 반환 np.isfinite(a)np.argmax(a) # 최대값 또는 최소값의 index를 반환 np.argmax(a, axis=1) # 가로 방향으로 한줄에 하나씩 반환 a.argsort() # 작은값부터 index를 반환 a.argsort()[::-1] # 거꾸로 반환 a[np.argmax(a)] #인덱스가 아닌 값을 반환# boolean index test_array[test_array > 3] # 조건에 해당하는 값만 출력 # fancy index a = np.array([2,4,6,8], float) b = np.array([0,0,1,3,2,1], int) a[b] # b의 값을 이용해서 a에서 index를 찾아서 value를 추출함 >>array([2., 2., 4., 8., 6., 4.])numpy data in/out
a = np.loadtxt("./example.txt", delimeter = "\\t") np.savetxt("int_data_2.csv", a_int_3, fmt="%.2e", delimiter=".")'개발자노트 > 네이버 부스트캠프 AI' 카테고리의 다른 글
[네부캠 AI tech] 2주차 주간회고 (11/13~11/17) (2) 2023.11.17 [네부캠 AI tech] 1주차 주간회고 (11/06~11/10) (0) 2023.11.10 [Pandas] 🐼판다스 기초 공부 (0) 2023.11.10 네이버 부스트캠프 AI Tech 6기 추가합격! (1) 2023.10.21 네이버 부스트캠프 AI tech 6기 1,2차 코딩테스트 회고 (0) 2023.10.10